Acknowledgements
All code in this neural net package was written by David Bailey of the University of Manchester.
Assumed knowledge
- Standard Template Library (STL) vectors.
Remarks
- All neural net classes are in the namespace
nnet. - This is by no means a complete guide to every feature available, at present at least.
Basic principles of an artificial neural network
This is a very basic introduction to the principles of a neural network (geared specifically at the way this package works). If you have any experience with neural networks you can safely skip this section.
Neurons are created to accept an arbitrary number of inputs, and based on these provide a single output value. The output is given by the neurons 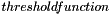 , which can be any given function of the neurons
, which can be any given function of the neurons 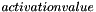 (see the Neuron Descriptions for the functions actually provided with this package).
(see the Neuron Descriptions for the functions actually provided with this package).
The activation value is given by multiplying each input by a pre calculated  depending on how important that input is, and summing these results. Each neuron can also be given a bias, depending on how important that neuron is to the network, but more on that later.
depending on how important that input is, and summing these results. Each neuron can also be given a bias, depending on how important that neuron is to the network, but more on that later.
Calculating these weights is the important part, and is what differentiates a well performing network from a bad one. This process is known as 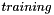 , and is performed by a training algorithm (see Training the network for the algorithms provided here). Basically, you provide the training algorithm with a set of data that you know the answers to (the result you would want the network to give you), and it changes the weights to give the best possible results for all the elements in the data set.
, and is performed by a training algorithm (see Training the network for the algorithms provided here). Basically, you provide the training algorithm with a set of data that you know the answers to (the result you would want the network to give you), and it changes the weights to give the best possible results for all the elements in the data set.
As a basic example, imagine a network composed of a single neuron that tells you if a food is bad for you or not. Say it is set up with three inputs, fibre content, fat content and colour. For simplicity, lets give the neuron a linear threshold function, so just a function that multiplies the activation value by a set constant, say  . The output of the network would be
. The output of the network would be
![\[ output=f(activation value)=k\times (fibrecontent\times weight_{fibre}+fatcontent\times weight_{fat}+colour\times weight_{colour}) \]](form_19.png)
The network is useless until the values of the weights are adjusted so that they give an accurate output. To do this, a large database of foods is required where the properties of colour, fibre and fat content are known, as well as some reliable value as to how healthy the food is. The training algorithm then modifies the weights to try and get the best match of the output to the expected value for each food in the database. When somebody comes along with a new food, its properties can be put into the network and a (hopefully) reliable value as to how healthy it is pops out the other end.
Ideally, once trained, the weight given to colour will be zero since that is completely irrelevant (ignoring artificial colourings). However, if the training sample has just a few blue foods, which just happen to be bad for you, then the training algorithm will wrongly ascribe a high weight.to the colour input. Also, if the training sample foods have pretty similar fat and fibre contents, but are radically differently healthy (say, maybe due to salt content), then the training algorithm will probably be unable to make any sense of the sample, and give useless weights. This emphasises the need to select a large and varied training sample (as well as setting up the network with meaningful inputs in the first place).
Realistically, a network will be composed of many neurons so that all 'cross effects' between the inputs are taken into account (where a weighting for one input needs to depend on other inputs as well). Here, the network would be built up with layers of neurons where the input for each neuron in a layer is the output from each neuron in the layer before. The final layer would have just one neuron, so that you get just one output for the network.
Creating and training a new neural net
The method used to create a new network varies slightly depending on the algorithm used to train it. Sections Building the neuron layers and Creating the network describe how to setup the network ready for training, which is common to all training algorithms. The BatchBackPropagationAlgorithm, BackPropagationCGAlgorithm and GeneticAlgorithm algorithms require the training data to be pre-stored in a nnet::NeuralNetDataSet class (section Building the training sample), and will train themselves over the whole data set. BackPropagationAlgorithm on the other hand performs one training step at a time to provide more control over each training step.
Descriptions of the algorithms are given in Training the network.
Building the neuron layers
Only simple nets can be built, where each neuron takes the outputs of all of the neurons in the previous layer as its inputs. Details about the neurons behaviour are given in Neuron Descriptions.
There are two methods, one where neurons can have different types, and a simpler one where all of the neurons have the same type.
All neurons of the same type
Building the neuron layers simply consists of creating an STL vector of integers with the number of neurons in each layer, including the output layer but excluding the input layer. The type of all of the neurons is set later when the network is built. So if a network takes 3 inputs, has two hidden layers with 6 neurons and 4 neurons respectively, and 2 outputs the layers would be set like this:
Neurons with different types}
These are set in a similar way, but instead of integers specifying the number of neurons in each layer, another STL vector of strings specifying the name of each neuron type is used, with the number of neurons set by the size of the vector. Currently available types (descriptions are given in Neuron Descriptions) are:
So if a network as in the previous example is to be built (with arbitrary neuron types):
Creating the network
Once the layer structure has been set up, the network can be created as follows, depending on which layer specification method was used.
All neurons of the same type
The type of the neurons is set by creating a neuron builder and passing its address to the network constructor. The names of available builders are the same as for the neurons, but with <tt>Builder</tt>'' on the end, for examplennet::LinearNeuronBuilder'' will build ``LinearNeuron''s.
Neurons with different types}
All that is needed here is the STL vectors of neuron names previously initialised and the number of inputs.
Random number generation
In each case, you can optionally use a random seed for the random number generator that sets the initial neuron weights by adding a boolean parameter at the end of the constructor arguments. Default is to use a random seed.
Note that currently the default implementation uses rand() for random numbers, and the random seed is taken from the current system time. If you require something more sophisticated modify the ``RandomNumberUtils.h'' file.
Building the training sample
A network can be trained without setting out the data sample into a nnet::NeuralNetDataSet using the BackPropagationAlgorithm, but large scale training is easiest using the other algorithms so this will be covered here.
Data is added to the nnet::NeuralNetDataSet by calls to addDataItem, with a vector of inputs and a vector of the expected outputs as the arguments. All items in the data set must have the same number of inputs and outputs; the first item you add sets these sizes for the whole data set. If you try and add an item where the input or output vectors are not the correct size, then an error will be printed to standard error and the item will be ignored.
For example:
Training the network
To train the network, a training algorithm is created with the network to be trained as the constructor argument, and a call to train is made with the number of training epochs and the training data. Currently available training algorithms are:
Training with BackPropagationAlgorithm
The Back Propagation Algorithm uses the back propagation method for determining the gradient of the error, and then gradient descent to modify the weights to minimise the error. It is very similar to the BatchBackPropagationAlgorithm except that it only performs one training step at a time to give more control over the training parameters at each step.
The algorithm class is constructed by giving it the network to be trained, and optionally values for 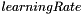 and
and 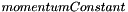 (defaults are 0.5 for both). The parameter is just a multiplier applied to the calculated change required for each weight, larger values will mean the weights will change more rapidly with each step. The previous steps' calculated change is also added to the current steps', but multiplied by the value. A value greater than or equal to one for this would stop the algorithm settling on a maximum because (at least) the full previous change is added as well.
(defaults are 0.5 for both). The parameter is just a multiplier applied to the calculated change required for each weight, larger values will mean the weights will change more rapidly with each step. The previous steps' calculated change is also added to the current steps', but multiplied by the value. A value greater than or equal to one for this would stop the algorithm settling on a maximum because (at least) the full previous change is added as well.
The train method is used to perform one training run, and returns the error. It takes a vector of the inputs and a vector of the required outputs, so if the first data item in the previous example is used for the step:
Training with BatchBackPropagationAlgorithm
This is essentially the same as BackPropagationAlgorithm, except it is supplied with a training sample which it will loop over itself. It can also be set do so repeatedly by specifying the number of epochs to run when calling the train method. The error for the most recent epoch is returned by train, and the errors from previous epochs can be retrieved as a vector with the getTrainingErrorValuesPerEpoch method.
Training with BackPropagationCGAlgorithm
This algorithm is similar to BatchBackPropagationAlgorithm except that it uses the conjugate gradient method to minimise the error instead of gradient descent. It offers three types of function to calculate the 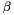 coefficient (see any detailed description of conjugate gradients) selected using the
coefficient (see any detailed description of conjugate gradients) selected using the setBetaFunction method. These are FletcherReves'',PolakRibiere'', and ``ConjugateGradient'', used as an enumeration as quoted. The default is FletcherReves.
Obtaining results
To get results from the neural network, the output method takes the inputs as an STL vector of doubles, and provides the results as an STL vector of doubles. So to determine if some animal is a donkey using a network trained from data of form of the data set in the previous example:
Saving a neural net to disk
Neural nets can either be saved as plain text or XML files, with the default being XML. To choose between the two make a call to NeuralNet::setSerialisationMode with either nnet::NeuralNet::PlainText or nnet::NeuralNet::XML.
The network can then be saved to disk by passing a C++ stream to serialise. For example:
The network can also of course be printed to standard output by calling serialise( std::cout ).
Loading a neural net from disk
A network can be loaded from disk by simply passing the filename and the serialisation mode as the constructor arguments. If the serialisation mode is not specified then XML is assumed. For example:
Note that there is currently no error checking when loading XML nets, if you try and load a plain text net as XML, or the file is not properly structured you will get a segmentation fault or runaway memory allocation. This is still being looked into.
Neuron Descriptions
The output from a neuron is given by its threshold function which is unique to each type of neuron. This is a function of the neurons activation value, which is calculated the same way for each type.
The activation value 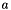 for a neuron with
for a neuron with 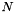 inputs,
inputs, 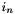 , each with weights
, each with weights 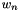 is given by
is given by
![\[ a=\sum_{n=1}^{N} i_{n}\times w_{n}+b\times w_{b} \]](form_27.png)
Where 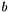 is a bias that can be assigned to a particular neuron (and
is a bias that can be assigned to a particular neuron (and 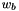 the bias' weight). The weights are initially random, and are then fine tuned by the training algorithms to try and give the desired output. The bias is set when the neuron is created but that process is done internally by the neuron builders. All current neuron builders set the bias to -1.
the bias' weight). The weights are initially random, and are then fine tuned by the training algorithms to try and give the desired output. The bias is set when the neuron is created but that process is done internally by the neuron builders. All current neuron builders set the bias to -1.
Some of the neurons have methods to change their behaviour. To get the neuron pointer to call these methods use <tt>NeuralNet::layer(layerNumber)->neuron(neuronNumber)</tt>'', where the numbers of available layers and neurons per layer can be found withNeuralNet::numberOfLayers()'' and ``NeuralNet::layer(layerNumber)->numberOfNeurons()'' respectively.
Linear Neuron
Linear neurons give, as the name suggests, a linear output between -1 and +1 with a gradient of 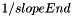 . The value of slopeEnd can be set using the
. The value of slopeEnd can be set using the LinearNeuron::setSlopeEnd(newValue) method. If the output is greater than +slopeEnd, then the output is limited to +1; any less than -slopeEnd and the output is limited to -1. Anywhere in between gives the expected linear output of 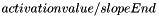 .
.
Sigmoid Neuron
The sigmoid neuron gives sigmoid (sort of resembles a slanted ``S'') output, 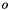 , of between 0 and 1 from the function
, of between 0 and 1 from the function
![\[ o=\frac{1}{1+e^{-a/r}} \]](form_33.png)
Where 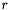 , the ``response'', can be set with the
, the ``response'', can be set with the SigmoidNeuron::setResponse(newValue) method. The default is 1.
Tan Sigmoid Neuron
This neuron gives a similar looking output to the sigmoid neuron, but between -1 and 1. The value is given by
![\[ o=tanh(s\times a) \]](form_35.png)
Where the value of  (the ``scale'') can be set with the
(the ``scale'') can be set with the TanSigmoidNeuron::setScale(newValue) method. The default is 1.
